Examples¶
The datasets used here are available at:
https://github.com/franrole/cclust_package/tree/master/datasets
Basic usage¶
In the following example, the CSTR dataset is loaded from a Matlab matrix using the SciPy library. The data is stored in X and a co-clustering model using direct maximisation of the modularity is then fitted with 4 clusters. The modularity is printed and the predicted row labels and column labels are retrieved for further exploration or evaluation.
from scipy.io import loadmat
from coclust.coclustering import CoclustMod
file_name = "../datasets/cstr.mat"
matlab_dict = loadmat(file_name)
X = matlab_dict['fea']
model = CoclustMod(n_clusters=4)
model.fit(X)
print(model.modularity)
predicted_row_labels = model.row_labels_
predicted_column_labels = model.column_labels_
For example, the normalized mutual information score is computed using the scikit-learn library:
from sklearn.metrics.cluster import normalized_mutual_info_score as nmi
true_row_labels = matlab_dict['gnd'].flatten()
print(nmi(true_row_labels, predicted_row_labels))
Advanced usage overview¶
from coclust.io.data_loading import load_doc_term_data
from coclust.visualization import (plot_reorganized_matrix,
plot_cluster_top_terms,
plot_max_modularities)
from coclust.evaluation.internal import best_modularity_partition
from coclust.coclustering import CoclustMod
# read data
path = '../datasets/classic3_coclustFormat.mat'
doc_term_data = load_doc_term_data(path)
X = doc_term_data['doc_term_matrix']
labels = doc_term_data['term_labels']
# get the best co-clustering over a range of cluster numbers
clusters_range = range(2, 6)
model, modularities = best_modularity_partition(X, clusters_range, n_rand_init=1)
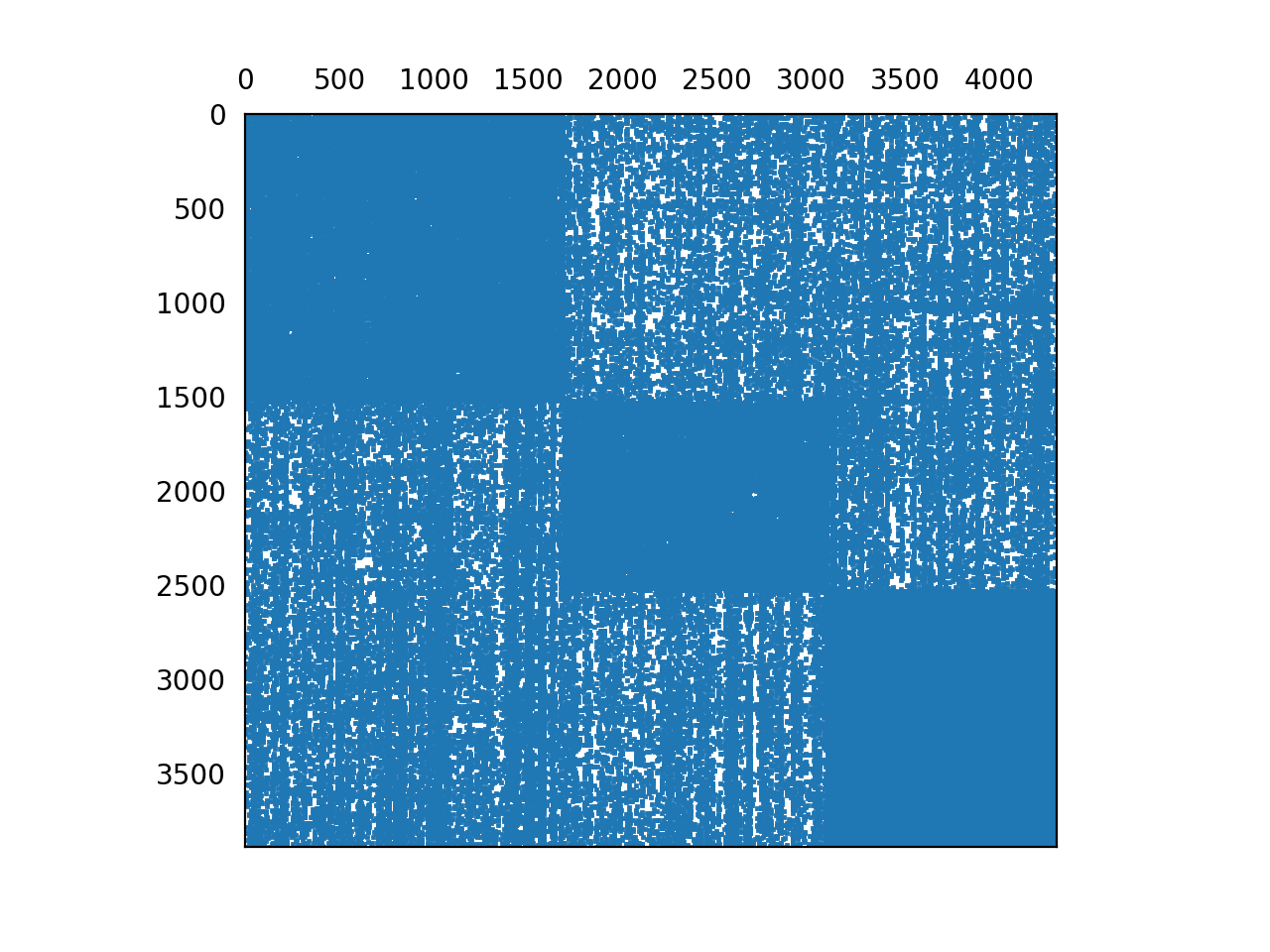
# plot the reorganized matrix
plot_reorganized_matrix(X, model)
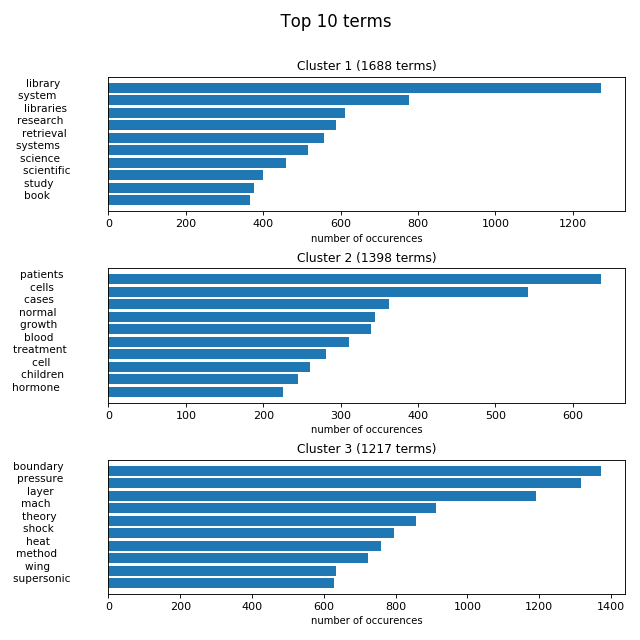
# plot the top terms
n_terms = 10
plot_cluster_top_terms(X, labels, n_terms, model)
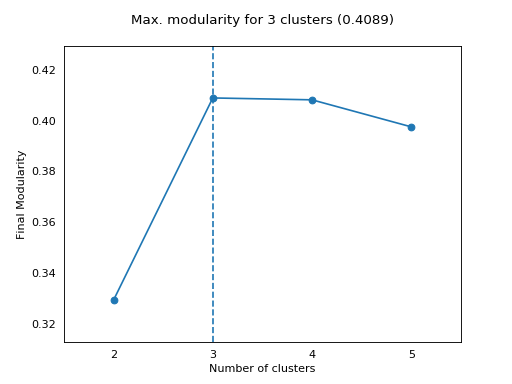
# plot the modularities over the range of cluster numbers
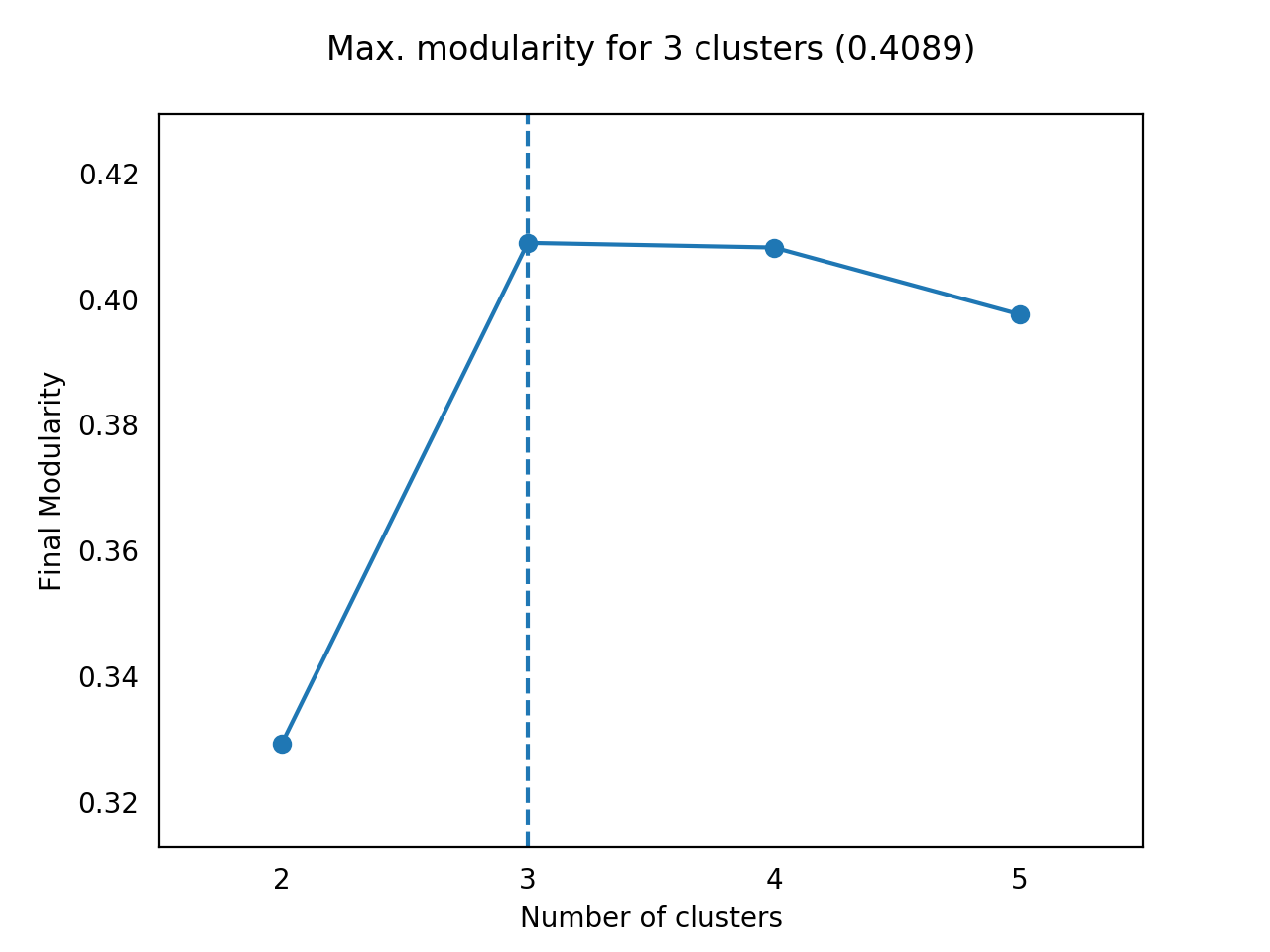
plot_max_modularities(modularities, range(2, 6))
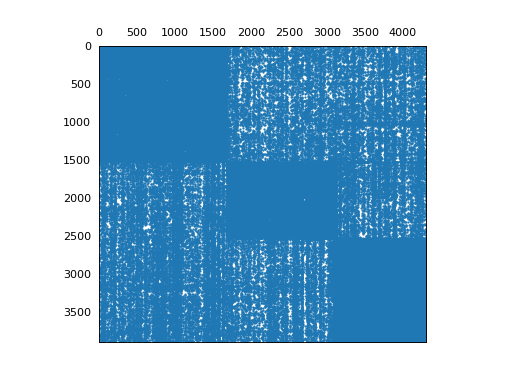
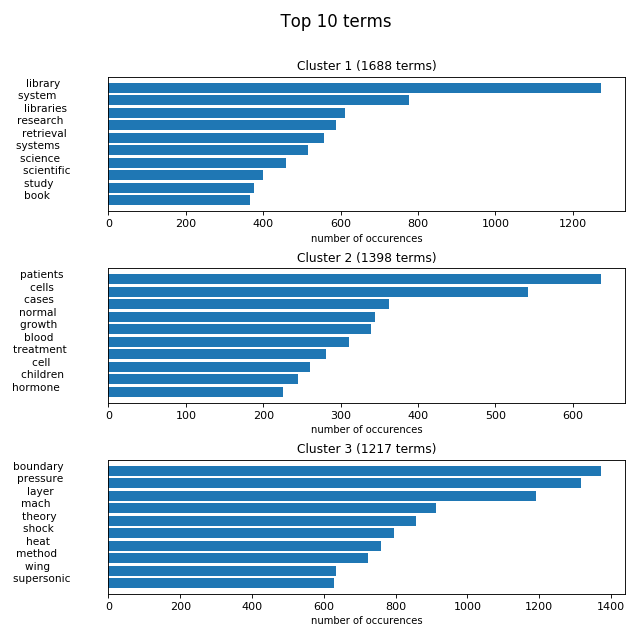
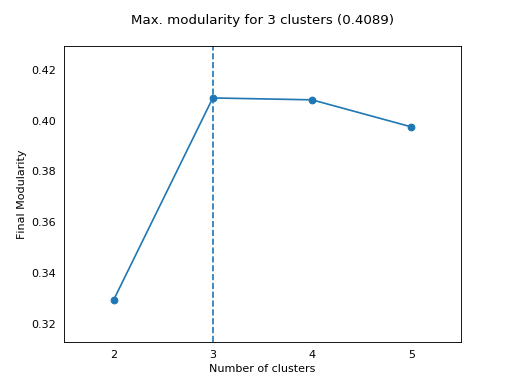
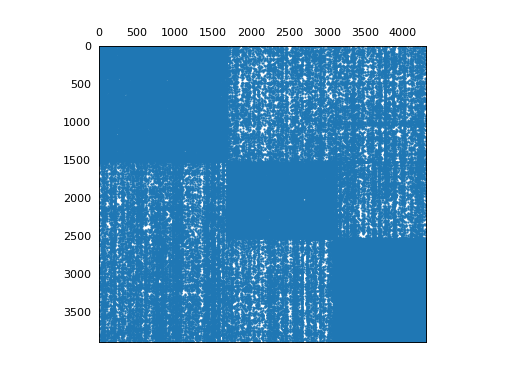{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
scikit-learn pipeline¶
from coclust.coclustering import CoclustInfo
from sklearn.datasets import fetch_20newsgroups
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.metrics.cluster import normalized_mutual_info_score
categories = [
'rec.motorcycles',
'rec.sport.baseball',
'comp.graphics',
'sci.space',
'talk.politics.mideast'
]
ng5 = fetch_20newsgroups(categories=categories, shuffle=True)
true_labels = ng5.target
pipeline = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('coclust', CoclustInfo()),
])
pipeline.set_params(coclust__n_clusters=5)
pipeline.fit(ng5.data)
predicted_labels = pipeline.named_steps['coclust'].row_labels_
nmi = normalized_mutual_info_score(true_labels, predicted_labels)
print(nmi)
More examples¶
More examples are available as notebooks: